
Apache Beam简介
Apache Beam是大数据的编程模型,定义了数据处理的编程范式和接口,它并不涉及具体的执行引擎的实现,但是,基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上,目前Dataflow、Spark、Flink、Apex提供了对批处理和流处理的支持,GearPump提供了流处理的支持,Storm的支持也在开发中。
综上所述,Apache Beam的目标是:
提供统一批处理和流处理的编程范式
能运行在任何可执行的引擎之上
为无限、乱序、互联网级别的数据集处理提供简单灵活、功能丰富以及表达能力十分强大的SDK。
在本文章中,将详细介绍一个Apache Beam 程序通过 kafkaIO 读取 Kafka 集群的数据,进行数据格式转换。数据统计后,通过 KafkaIO写操作把消息写入 Kafka 集群。最后把程序运行在 Flink 的计算平台上。
开发环境安装
本文使用Centos安装开发需要的Kafka和Flink
系统版本:Centos 7
Kafka 版本:kafka_2.10-0.10.1.1.tgz (百度网盘,提取码: gp6e)
Flink 版本:flink-1.5.2-bin-hadoop27-scala_2.11.tgz (百度网盘,提取码: cqdi)
Kafka安装和运行
上传Kafka到服务器,例如:/home目录,并解压缩
tar xvf kafka_2.10-0.10.1.1.tgz由于Kafka需要ZooKeeper,所以先启动ZooKeeper
cd /home/kafka_2.10-0.10.1.1
bin/zookeeper-server-start.sh config/zookeeper.properties &启动Kafka
bin/kafka-server-start.sh config/server.properties &Flink安装和运行
上传Flink到服务器,例如:/home目录,并解压缩
tar xvf flink-1.5.2-bin-hadoop27-scala_2.11.tgz启动Flink
cd /home/flink-1.5.2/bin
./start-cluster.sh在浏览器查看Flink运行情况(192.168.233.133为示例IP)
http://192.168.233.133:8081/创建一个Maven项目
文章最后,附有完整Maven项目下载地址
在 pom 文件中添加依赖
beam版本:2.4.0
<!-- beam -->
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-kafka</artifactId>
<version>{beam.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-core-java</artifactId>
<version>{beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-flink_2.11</artifactId>
<version>${beam.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- flink -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime_2.11</artifactId>
<version>1.5.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.5.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-metrics-core</artifactId>
<version>1.5.2</version>
<scope>provided</scope>
</dependency>
<!-- kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.1.1</version>
</dependency>在 pom 文件中添加打包插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.suyuening.beam.BeamFlinkKafka</mainClass> <!--这里运行类!也就是入口类 -->
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>Beam完整示例代码
package com.suyuening.beam;
import org.apache.beam.runners.core.java.repackaged.com.google.common.collect.ImmutableMap;
import org.apache.beam.runners.flink.FlinkRunner;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.kafka.KafkaIO;
import org.apache.beam.sdk.io.kafka.KafkaRecord;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.*;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.apache.beam.sdk.values.KV;
import org.apache.beam.sdk.values.PCollection;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.joda.time.Duration;
/**
* 类描述: Apache Beam 程序通过 kafkaIO 读取 Kafka 集群的数据,进行数据格式转换。数据统计后,通过 KafkaIO
* 写操作把消息写入 Kafka 集群。最后把程序运行在 Flink 的计算平台上。
* <p>
* 系统版本 centos 7
* </p>
* <p>
* Kafka 集群版本: kafka_2.10-0.10.1.1.tgz
* </p>
* <pFlink 版本:flink-1.5.2-bin-hadoop27-scala_2.11.tgz
* </p>
*
* @author suyuening
* @version 1.0
* @date 2020/1/20 13:10
*/
public class BeamFlinkKafka {
/**
* kafka 的服务器地址和端口,多个用逗号分隔。例如:
* 192.168.233.1:9092,192.168.233.2:9092,192.168.233.3:9092
*/
private static final String BOOTSTRAP_SERVERS = "192.168.233.133:9092";
/** 要读取的 kafka 的 topic */
private static final String KAFKA_READ_TOPIC = "testmsg";
/** 要写入的 kafka 的 topic */
private static final String KAFKA_WRITE_TOPIC = "senkafkamsg";
public static void main(String[] args) {
// 创建管道工厂
PipelineOptions options = PipelineOptionsFactory.create();
// 显式指定 PipelineRunner:FlinkRunner 必须指定如果不制定则为本地
options.setRunner(FlinkRunner.class);
// 设置相关管道
Pipeline pipeline = Pipeline.create(options);
// 这里 kV 后说明 kafka 中的 key 和 value 均为 String 类型
PCollection<KafkaRecord<String, String>> lines = pipeline
.apply(KafkaIO.<String, String>read().withBootstrapServers(BOOTSTRAP_SERVERS) // 必需设置 kafka 的服务器地址和端口
.withTopic(KAFKA_READ_TOPIC)// 必需设置要读取的 kafka 的 topic
.withKeyDeserializer(StringDeserializer.class)// 必需序列化 key
.withValueDeserializer(StringDeserializer.class)// 必需序列化 value
.updateConsumerProperties(ImmutableMap.<String, Object>of("auto.offset.reset", "earliest")));// 这个属性kafka最常见的
// 为输出的消息类型。或者进行处理后返回的消息类型
PCollection<String> kafkadata = lines.apply("Remove Kafka Metadata",
ParDo.of(new DoFn<KafkaRecord<String, String>, String>() {
private static final long serialVersionUID = 1L;
@ProcessElement
public void processElement(ProcessContext ctx) {
System.out.println("输出的分区为 ----:" + ctx.element().getKV());
ctx.output(ctx.element().getKV().getValue());// 其实我们这里是把"张海 涛在发送消息 ***"进行返回操作
}
}));
PCollection<String> windowedEvents = kafkadata
.apply(Window.<String>into(FixedWindows.of(Duration.standardSeconds(5))));
PCollection<KV<String, Long>> wordcount = windowedEvents.apply(Count.<String>perElement()); // 统计每一个 kafka 消息的
// Count
PCollection<String> wordtj = wordcount.apply("ConcatResultKVs", MapElements.via( // 拼接最后的格式化输出(Key 为 Word,Value为
// Count)
new SimpleFunction<KV<String, Long>, String>() {
private static final long serialVersionUID = 1L;
@Override
public String apply(KV<String, Long> input) {
System.out.println("进行统计:" + input.getKey() + ": " + input.getValue());
return input.getKey() + ": " + input.getValue();
}
}));
wordtj.apply(KafkaIO.<Void, String>write().withBootstrapServers(BOOTSTRAP_SERVERS)// 设置写会 kafka 的集群配置地址
.withTopic(KAFKA_WRITE_TOPIC)// 设置返回 kafka 的消息主题
// .withKeySerializer(StringSerializer.class)// 这里不用设置了,因为上面 Void
.withValueSerializer(StringSerializer.class)
// Dataflow runner and Spark 兼容, Flink 对 kafka0.11 才支持。我的版本是 0.10 不兼容
// .withEOS(20, "eos-sink-group-id")
.values() // 只需要在此写入默认的 key 就行了,默认为 null 值
); // 输出结果
pipeline.run().waitUntilFinish();
}
}执行mvn clean package打包
通过Apache Flink Dashboard 提交 job
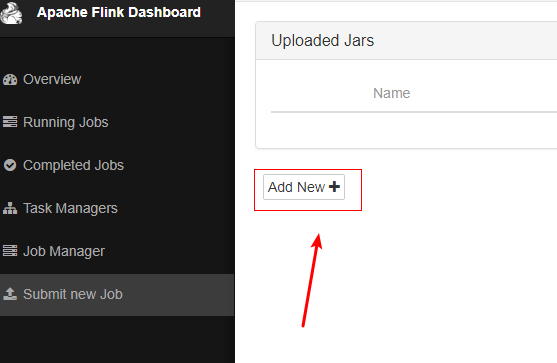
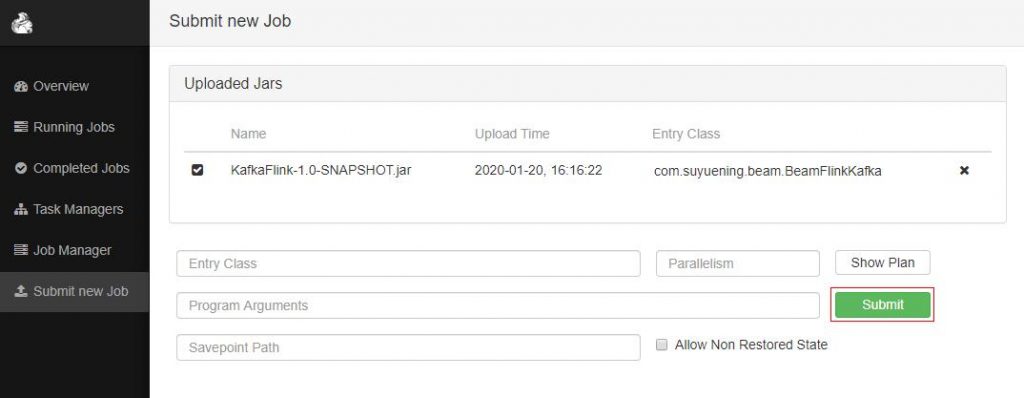

测试Job
添加Kafka主题
cd /home/kafka_2.10-0.10.1.1
bin/kafka-topics.sh --create --zookeeper 192.168.233.133:2181 --replication-factor 1 --partitions 3 --topic testmsg
bin/kafka-topics.sh --create --zookeeper 192.168.233.133:2181 --replication-factor 1 --partitions 3 --topic senkafkamsg启动Kafka生产者,生产消息到testmsg。在控制台输入测试字符串
cd /home/kafka_2.10-0.10.1.1
bin/kafka-console-producer.sh -broker-list 192.168.233.133:9092 -topic testmsg启动Kafka消费者,消费senkafkamsg主题,查看Flink处理消息后的结果
bin/kafka-console-consumer.sh --bootstrap-server 192.168.233.133:9092 --from-beginning --topic senkafkamsg效果图
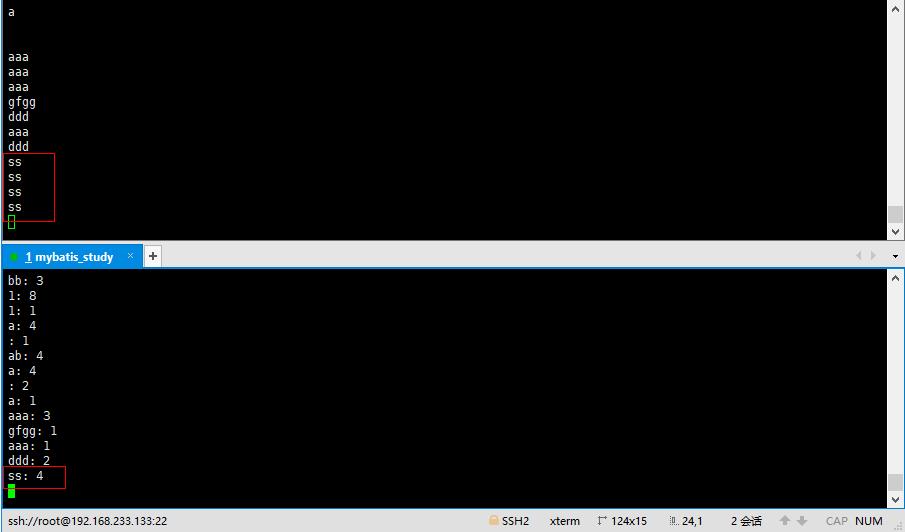
完整Maven项目下载地址:https://github.com/infoplat/KafkaFlink

近期评论